

5 MINUTES TO SNAP-SHOT GENETICS
รหัสพันธุกรรม (Coding) มีด้วยกันสามรูปแบบ
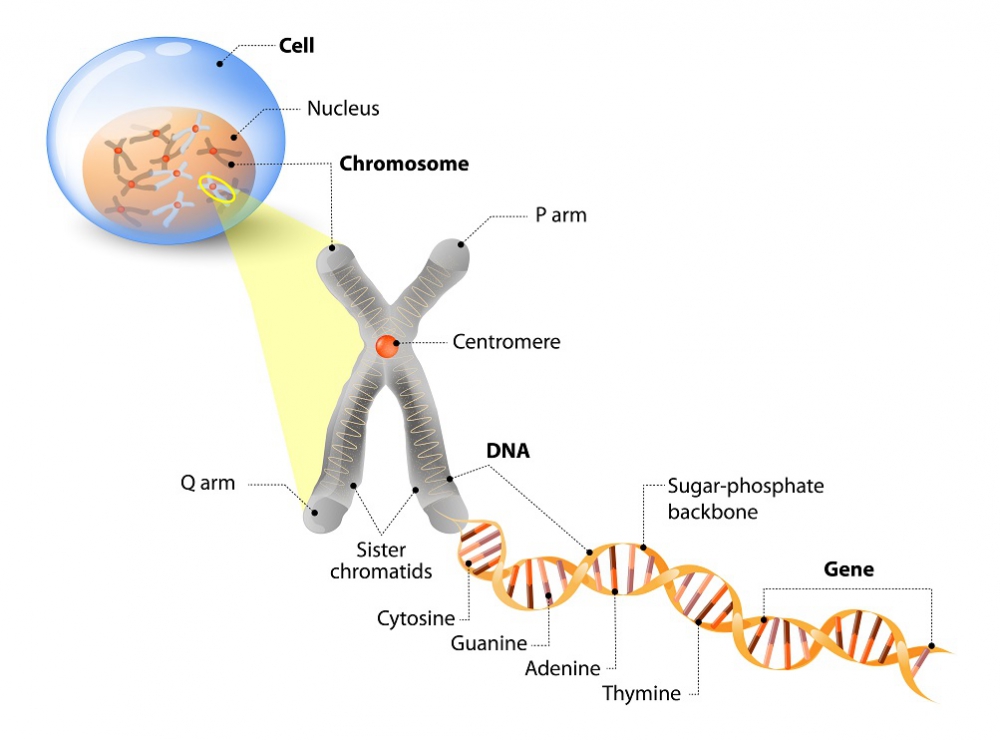
1. DNA ที่อยู่บนโครโมโซม ประกอบด้วยนิวคลีโอไทด์ 4 ชนิด ได้แก่ Adenine(A) Thymine(T) Guanine(G) Cytosine(C) การจับคู่ของ A-T และ G-C เป็นการจับคู่ของเบส

รูปที่ 1 นิวคลีโอไทด์เกิดจากการรวมของนิวคลีโอไซด์ และหมู่ฟอสเฟต โดยนิวคลีโอไซด์ประกอบด้วยน้ำตาลเพนโตส และเบสจำนวน 4 ชนิด คือเพียวรีน ได้แก่ A,G และ พิริมิดีน ได้แก่ C,T
2.ยีนคือทำหน้าที่ควบคุมและถ่ายทอดทางพันธุกรรม โดยจะมีส่วน อินตรอน (Intron) ซึ่งจะไม่ถูกใช้ในการแแปลรหัส (Translation) เป็นโปรตีน และส่วน เอ็กซอน (Exon) ที่จะถูกแปลรหัสเป็นโปรตีน

3.กระบวนการถอดรหัสพันธุกรรม (Transcription) ใช้ DNA เป็นต้นแบบจะมีการเปลี่ยนแปลงนิวคลีโอไทด์ ชนิด Thymine(T) เป็น Uracil(U) จะเรียกผลผลิตจากการถอดรหัสพันธุกรรมนี้ว่า mRNA ซึ่ง mRNA ก็จะมีนิวคลีโอไทด์ 4 ชนิด ได้แก่ A, U, G, C โดยในกระบวนการสร้าง mRNA นี้จะมีการตัดอินทรอนออกไป เรียกกระบวนการ Splicing และ mRNA ที่ผ่านกระบวนการแปลรหัสนี้ 3 ตัวจะสามารถสร้างกรดอะมิโน 1 ชนิด เราจะเรียกว่าโคดอน (Codon)
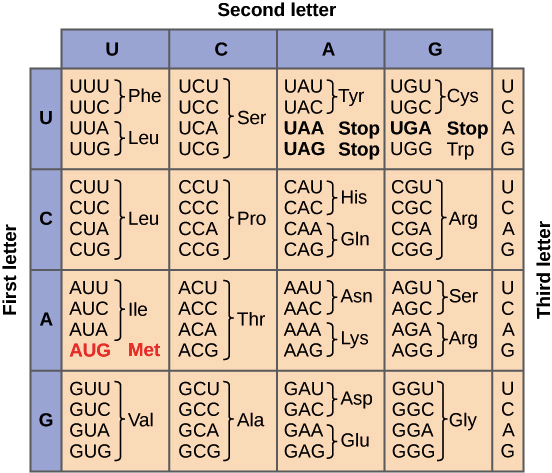
รูปที่ 2 แสดงการแปลรหัสสังเคราะห์โปรตีน โดยจะมีรหัสสำหรับเริ่ม (Start Codon) คือ AUG ซึ่งเป็นรหัสของกรดอะมิโนเมทไธโอนีน (Methionine) และรหัสที่บอกให้หยุดการสังเคราะห์กรดอะมิโน(Stop Codon) จะมีด้วยกัน 3 รหัสคือ UAA, UAG, UGA ดังนั้น Uracil จึงทำหน้าที่สำคัญในการบอกจุดเริ่มและจุดสุดท้ายของการสังเคราะห์กรดอะมิโน
ตัวอย่างการแปลรหัส
เพื่อให้เข้าใจมากขึ้น จึงขอยกตัวอย่างดังนี้
1) กำหนดให้ Start Codon คือ "CAT"
2) กำหนดให้ Stop Codon คือ "DOG"
สมมติว่าลำดับคือ BOHJKRDHQWESDRTGFYCATOWLFOXCATRATFOXOWLOWLRATDOGCTRAT
จะได้เป็น BOHJKRDHQWESDRTGFYCATOWLFOXCATRATBATFOXOWLOWLRATDOGCTRAT นั่นเอง
ซึ่งในการทำงานจริง การมานั่งหา Start และ Stop Codon ใช้เวลาค่อนข้างนาน อีกทั้งยังต้องแปลงรหัสนิวคลีโอไทด์เป็นกรดอะมิโนอีก จึงมีการใช้โปรแกรมมาช่วยในการค้นหา เรียกโปรแกรมนี้ว่า Open Reading Frame (ORF) Finder
โปรแกรม ORF Finder
หนึ่งในโปรแกรมที่นิยมใช้กันคือผ่าน NCBI (https://www.ncbi.nlm.nih.gov/orffinder/) โดยเราสามารถอัพโหลดไฟล์เข้าไป โดยไฟล์ลำดับนิวคลีโอไทด์จะต้องอยู่ในรูป FASTA ฟอร์แมตเสียก่อน